Designed for Monkeys
Most programmers don’t know the intricacies of parallel programming. That’s why we designed a library even a Monkey could use.
Example code for an algorithm that computes whether a sequence of parentheses is well matched:
/*
* Test if a sequence of 1's or -1's is "matched", treating
* 1's as open parens and -1's as close parens.
* (String parsing omitted)
*/
bool paren_match(Sequence<int> &seq) {
// C++11 lambda functions
auto plus = [](int a, int b) {
return a + b;
};
auto min = [](int a, int b) {
return a < b ? a : b;
};
// Compute a prefix sum
seq.scan(plus, 0);
int int_max = std::numeric_limits<int>::max();
// A well matched sequence has a net sum of 0 and
// never drops under zero
return seq.get(seq.length() - 1) == 0 &&
seq.reduce(min, int_max) >= 0;
}
A more compact version using functions (plus, min_elem) supplied by our libraries:
bool paren_match(Sequence<int> &seq) {
seq.scan(Lambda::plus, 0);
return seq.get(seq.length() - 1) == 0 &&
seq.reduce(Lambda::min_elem, INT_MAX) >= 0;
}
Lightning Fast Cluster Computing
We believe that cluster computing is the future. Companies from Google to Amazon hold vast compute resources, but these resources cannot be combined onto a single chip. Applications that want to remain revelant and fast need to scale accross multiple nodes.
Lambda++ uses the Message Passing Interface (MPI) to minimize communication accross nodes in a cluster and to explicitly handle memory allocation. This means that your programs aren’t blocked by high network latencies or by memory addresses jumping back and forth accross nodes.
Within a node, Lambda++ uses OpenMP to optimize for high speed shared memory architectures. The library uses external devices (like the 40-core Xeon Phi) when possible to squeeze every ounce of power from the cluster.
Lambda++ uses randomized algorithms to balance load accross the cluster. This ensures that one processor doesn’t hold up the compute task, but avoids the overhead of synchronization in traditional work stealing approaches.
To sweeten the deal, Lambda++ adapts to those pesky architectures where some compute resources dwarf others in performance! We do this by quickly profiling available compute resources before the work is distributed.
The Versatility of Lambda
If you’ve ever tried a functional language like Haskell or SML, you know that
functions are awesome! Being able to describe an algorithm in terms of the
operations it’s composed of, and building on top of a toolkit of “higher-order”
functions like map, reduce, filter, and scan, is incredibly powerful. On
top of their value to a programmer’s efficiency, these primitives lend
themselves nicely to parallelization.
With Lambda++, we bring these benefits to C++. Using OpemMPI on top of C++11, we
have been able to implement a library of these functions, called the Sequence
library. The API design is adapted from a class at Carnegie Mellon, which uses a
similar (non-parallelized) library to solve programs from dynamic programming to
graph contraction.
Lambda++ is familiar and useful, enabling the user to achieve great performance while retaining expressiveness.
Some Preliminary Results
We know that a library for parallel programming lives or dies by it’s performance, so we’ve taken care to optimize for many types of usage patterns. Take a look at the following chart:
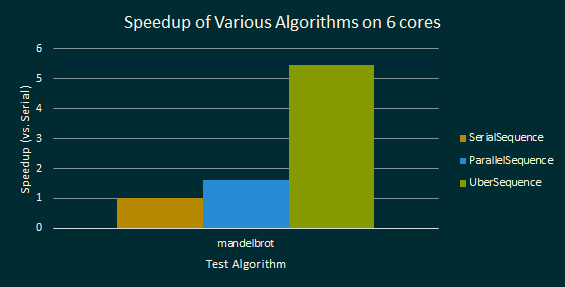
This chart shows a bunch of stuff. Let’s break it down:
mandelbrotis a test case that computes elements of the Mandelbrot SetSerialSequence,ParallelSequence, andUberSequenceare all implementations of the abstractSequenceinterface, which just declares operations likemap,scan,reduce, etc.ParallelSequenceandUberSequenceare parallelized versions of this abstraction.UberSequencegets a near perfect speedup on themandelbrottest, doing much better thanParallelSequence, even though both are parallel algorithms.
What’s the cause of this difference? Let’s use another graph to find out!
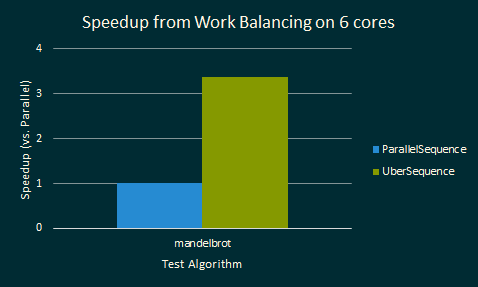
Here we see the speedup of UberSequence relative to ParallelSequence instead
of SerialSequence. The title of this graph mentions “work balancing”: indeed,
UberSequence is work balancing the input to determine where to allocate work!
In doing this, even though we have to partition work across the 6 execution contexts of the machine, we can still get a large speedup!
These tests were run across a single GHC hex-core Intel machine. Let’s kick it
up a notch. Here’s the performance of UberSequence relative to
SerialSequence on the Latedays cluster using various amounts of computing
resources.
Here’s we’re plotting the performance of the mandelbrot test across up to four
nodes in a cluster on Latedays. The “0” datapoint represents the serial
version’s performance in this cluster.
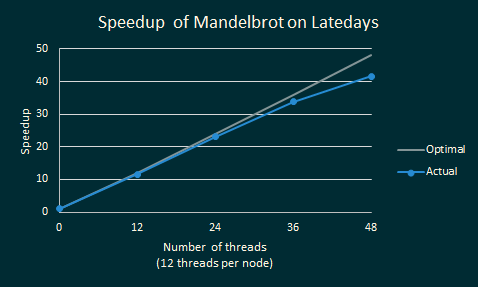
Even as we increase the number of execution contexts, we still manage to get near-optimal speedups!
Here’s the same analysis for paren_match, an algorithm that computes whether
a sequence of parentheses is well-matched:
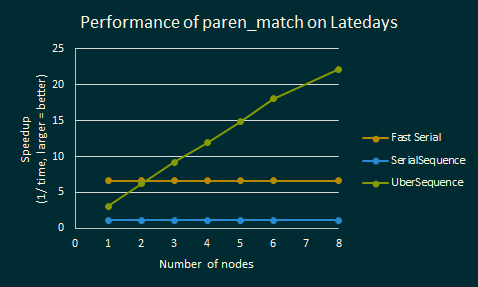
The first thing you’ll notice is that the speedup is not quite as large as it
was for mandelbrot. This is to be expected though. Mandelbrot set generation
is completely data parallel once you’ve determined the pixel, whereas matching
parentheses uses scan and reduce, both of which have logarithmic span.
Despite this, the parallel version of our code runs quite quickly across multiple nodes. It’s important to note that as we continue to push upwards, say to 2 billion elements, we no longer have enough memory to fit the dataset into a single node, so any serial implementation simply will not work.
Where to Go Now
We hope you enjoyed the quick introduction to our project. Right now we are profiling the performance of our library. We are very exciting about seeing our project to completion.
If you’re a judge, select us for the Parallel Contest in Carnegie Mellon on the 11th of May for more information! We will show:
- Performance results for a large number of nodes
- Work balancing capabilities of our library
- Code samples and results for more application, like useful dynamic programming programs
- Comparisons with libraries like CUDA Thrust
And we will delve into more details about our algorithms. For now, there are a number of other resources you can check out:
We’re pretty excited about our project, and we hope we’ve manged to share that with you.
This site is still a work in progress! We’ll be revising it with more up-to-date information soon, so be sure to check back!